Scheduled Job Lambda Functions
With a great degree of success, JBS teams have utilized Lambda functions to serve RESTful APIs, process data, and handle other tasks across various...
Introduction
With a great degree of success, JBS teams have utilized Lambda functions to serve RESTful APIs, process data, and handle other tasks across various projects. The serverless architecture afforded by AWS Lambda gives developers huge amounts of flexibility by removing the need for managed infrastructure – we can simply focus on the code.
However, due to the few limitations imposed by a Lambda function’s underlying design, there can occasionally be a small hurdle. One of the first interesting problems our teams came across when writing Lambda functions (now years ago) was a fundamental design challenge: How can we support a typically scheduled job on a Lambda function?
At the time, Lambda functions had a 5-minute timeout, which has since been upgraded to a full 15 minutes. For a REST API running on a Lambda, it is often undesirable to leverage that full 15-minute interval. Most APIs should be responsive within a few seconds and allowing even some requests to hit that interval maximum could prove deadly from a billing perspective in the long run.
Fortunately, AWS has an out-of-the-box solution that can be leveraged to create your very own cronjob Lambda in a way that doesn’t require you to worry about long-running function invocations, increasing concurrent executions, and costly GB-seconds in compute time.
EventBridge (formerly CloudWatch Events)
Enter EventBridge triggers for Lambda functions. What was once known as CloudWatch Events has been rebranded “EventBridge” to more accurately label the underlying asynchronous messaging bus architecture? The relevant functionality provided to us by EventBridge is the fact that it can be a trigger for a Lambda function. And, conveniently for our problem scenario, EventBridge events can be scheduled using a cron-like syntax within AWS.
The basic building blocks of creating a cronjob Lambda are already present in AWS; but the problem then becomes – do we really want to set our Lambda function timeout to 15 minutes to support long-running scheduled jobs? As mentioned above, the answer is almost always “no.”
Event Lambda Architecture
The simplest solution our teams found was to create a secondary “Event Lambda” – a carbon-copy of our main API Lambda function that has more memory and a higher timeout. Since the event Lambda will only be executing a handful of scheduled jobs a few times a day at most, it makes sense to increase the memory footprint of the event Lambda. Also, we’re now able to leverage the full 15-minute timeout provided by Amazon to ensure we can do as much processing as possible within a single invocation. Since our number of invocations on the event Lambda should be low compared to a Lambda function serving a public API, for example, the cost difference should be negligible.
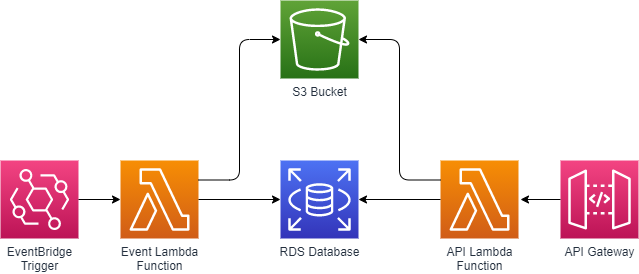
Above: A simple API+Event Lambda Architecture
When creating a secondary Event Lambda within your application architecture using the same application code, the design and connectivity remain the same across both Lambda functions. The same application code is running on the Event Lambda, so the connectivity to other resources utilized by your application on the main Lambda function will need to be established on it.
Creating an Event Lambda via Terraform
Using Terraform Enterprise allows us to maintain resource state in a centralized backend, with configuration files managed in version control. Infrastructure as Code is a powerful tool, but the details here can be a little tricky to keep it truly beneficial from a workflow and deployment perspective. Namely: how can we deploy a secondary Lambda function without copying and pasting our Lambda function Terraform configuration? Maintaining two sets of the same Lambda configuration for an application can lead to problems in the future if, for example, a developer is unaware of the secondary event Lambda configuration altogether.
Let’s take a look at a simple configuration example where we might achieve something similar to the previous architecture example figure.
Our first assumption in this process is that your application code is zipped into a single archive file locally and you are ready to upload (a popular way to do this with Python projects is by using Zappa’s package command):
resource "aws_s3_bucket" "code_deploy_bucket" {
bucket = "code-deploy-bucket"
acl = "private"
}
resource "aws_s3_bucket_object" "lambda_code" {
bucket = aws_s3_bucket.code_deploy_bucket.id
key = "api-code.zip"
source = "./api-code.zip"
etag = filemd5("./api-code.zip")
}We create an S3 bucket, mark it as private, and then tell Terraform to upload the local file “api-code.zip” into that bucket – but only if it’s MD5 hash has changed from our last deployment (the etag property handles this logic).
Next, we define our main application Lambda function:
resource "aws_lambda_function" "main_application_lambda" {
depends_on = [
aws_s3_bucket.code_deploy_bucket,
aws_s3_bucket_object.lambda_code
]
s3_bucket = aws_s3_bucket.code_deploy_bucket.bucket
s3_key = "api-code.zip"
source_code_hash = filebase64sha256("./api-code.zip")
publish = true
function_name = "my-application"
description = "Main Application Lambda"
role = "arn:aws:iam::12345678:role/LambdaExecutionRole"
handler = "handler.lambda_handler"
memory_size = 1536
timeout = 30
runtime = "python3.8"
environment {
variables = {
DB_HOST = "my-rds-host.amazonaws.com"
DB_USER = "db_user"
DB_PASS = "db_pass"
S3_BUCKET = "my-s3-bucket.s3.amazonaws.com"
}
}
}We reference the same “api-code.zip” filename – this time from our S3 bucket. The usual suspects are with respect to a bare-bones Lambda configuration: name, description, execution role, handler, memory, timeout, and runtime settings. Note that we have the memory configuration option set to 1.5GB, with a 30-second invocation timeout.
At the end of the main application’s Lambda configuration is a small set of environment variables. This is a common way to let your application code access runtime configuration settings specific to your needs. In our example above, I provide some basic database connectivity options for our RDS instance and a reference to another S3 bucket that houses application assets (not defined in the example Terraform).
All is looking good; our next step is the event Lambda function:
resource "aws_lambda_function" "event_application_lambda" {
depends_on = [
aws_s3_bucket.code_deploy_bucket,
aws_s3_bucket_object.lambda_code,
aws_lambda_function.main_application_lambda,
]
s3_bucket = aws_s3_bucket.code_deploy_bucket.bucket
s3_key = aws_lambda_function.main_application_lambda.s3_key
source_code_hash = aws_lambda_function.main_application_lambda.source_code_hash
publish = true
function_name = "${aws_lambda_function.main_application_lambda.function_name}-events"
description = "${var.lambda_function_description} Scheduled Events"
role = aws_lambda_function.main_application_lambda.role
handler = aws_lambda_function.main_application_lambda.handler
memory_size = 2048
timeout = 900
runtime = aws_lambda_function.main_application_lambda.runtime
environment {
variables = aws_lambda_function.main_application_lambda.environment[0].variables
}
}As you can see, we are now referencing properties directly from the main_application_lambda resource as defined in our Terraform configuration. This prevents us from having to maintain a large amount of duplicate configuration values. We reference the same code file in our S3 bucket, and we dynamically build a new Lambda function name and description to accurately identify this function as the “Event” Lambda function.
The important callouts for the event Lambda configuration are twofold: our increased memory size and timeout options, and the environment variables. While purely optional, I’ve opted to increase our event Lambda function’s timeout and memory options so we can have additional time and resources to carry out long-running jobs we may want to execute in the future. The environment block is also dynamically carrying over all environment variables from the main Lambda function’s configuration – eliminating a potential headache in maintaining two sets of the same values.
We’re now ready for the final step: scheduling a job for the event Lambda to execute!
resource "aws_cloudwatch_event_rule" "example_event" {
name = "application.jobs.example"
description = "Scheduled event for Lambda"
schedule_expression = "cron(0 * * * ? *)"
role_arn = "arn:aws:iam::12345678:role/LambdaExecutionRole"
}
resource "aws_cloudwatch_event_target" "example_event" {
rule = aws_cloudwatch_event_rule.example_event.name
target_id = "scheduled-event-example-job"
arn = aws_lambda_function.event_application_lambda.arn
depends_on = [
aws_cloudwatch_event_rule.example_event,
]
input_transformer {
input_paths = {
"detail-type":"$.detail-type",
"resources":"$.resources",
"detail":"$.detail",
"id":"$.id",
"source":"$.source",
"time":"$.time",
"region":"$.region",
"version":"$.version",
"account":"$.account"
}
input_template = <<EOF
{"time": <time>, "detail-type": <detail-type>, "source": <source>,"account": <account>, "region": <region>,"detail": <detail>, "version": <version>,"resources": <resources>,"id": <id>,"kwargs": {}}
EOF
}
}
resource "aws_lambda_permission" "cloudwatch_scheduled_event_invoke_permission" {
depends_on = [
aws_cloudwatch_event_target.example_event,
]
statement_id = "MyApplicationEventInvokeExampleJob"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.event_application_lambda.function_name
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.example_event.arn
}First, we create a CloudWatch Event Rule resource, which contains a reference (in our example, a Python module reference) to the application method we want to execute. The event rule also contains a cron-like expression used for scheduling its trigger frequency.
Next, we create an “event target” resource, which is the target resource that is referenced when the event is triggered on the provided schedule. The ARN we specify tells EventBridge that the triggered event should be handed off to our event Lambda function. In our example, we use an input transformer configuration that works well with Zappa-packaged application handlers.
Finally, we create an AWS Lambda permission resource and attach it to our event Lambda function. This is essentially defining CloudWatch Events (EventBridge) as a possible invocation trigger for our event Lambda function.
Final Steps and Further Reading
With a functioning event Lambda function, you now no longer have to worry about creating a dedicated EC2 instance for long-running jobs (up to the 15-minute execution mark).
The following references can provide additional information and insight:
- EventBridge cron expression syntax documentation also includes additional information about how to schedule event triggers
- Terraform provides an extensive reference of AWS resource documentation
- Quickly package and deploy code with Zappa
The JBS Quick Launch Lab
Free Qualified Assessment
Quantify what it will take to implement your next big idea!
Our assessment session will deliver tangible timelines, costs, high-level requirements, and recommend architectures that will work best. Let JBS prove to you and your team why over 24 years of experience matters.



