The Evolution of Maintainable Lambda Development Pt 1
AWS Lambda is a very popular tool for deployments at JBS. As an AWS Partner, we have repeatedly espoused the benefits of serverless architectures as we have experienced the success it has offered many
Introduction
AWS Lambda is a very popular tool for deployments at JBS. As an AWS Partner, we have repeatedly espoused the benefits of serverless architectures as we have experienced the success it has offered many of our clients when it comes to flexibility in deployments and scaling. When serverless architectures are used for low-traffic fledgling projects they are extremely cheap due to the free tier allotments, and as traffic grows cost increases only with those resources being used and the scaling requires less effort and cost than many other containerized orchestration architectures.
We've written on serverless architectures both in general and regarding specific use cases such as generating PDFs and using GeoDjango in lambda using Zappa. What we want to explore in this series is how serverless architectures affect development practices and project management, and how different options in this ever-evolving arena offer new and exciting ways for engineers to design reliable and manageable serverless applications.
We will begin by re-visiting the basics of what lambda provides from the perspective of investigating the service for the first time, identifying some of the pain points as a serverless project built around lambda starts to grow, then leave some questions open to visit specific solutions in the second part of the series.
We will then continue to explore how JBS currently manages robust serverless projects, then lastly we'll investigate how new offerings from AWS with the introduction of lambda from Docker images continue to close the gap between development and deployment consistency.
Where Most People Start
AWS provides excellent getting started guides that detail the different ways you can deploy code to Lambda. Using the AWS Console to configure and modify code is a typical way to get introduced to Lambda. All the functionality that is exposed programmatically with AWS APIs and SDKs is available manually in the Management Console.

Lambda provides an easily searchable UI to organize your functions
Managing much more than a "Hello World" or one-time throwaway function directly in the Management Consoles quickly leads to at least a few problems:
Code Management
It is difficult to impossible to manage lambda deployments of significant size or complexity in the AWS Management Console. In the Management Console, there is the ability to manage multiple files so that a function is more of a "project" than just a single large file. However, there are limitations in what languages can be edited in the UI, and on the size of the projects you can manage this way, as stated in the documentation:
To add libraries, or for languages that the editor doesn't support, or to create a function deployed as a container image, upload a deployment package. If your deployment package is larger than 50 MB, choose to Upload a file from Amazon S3.
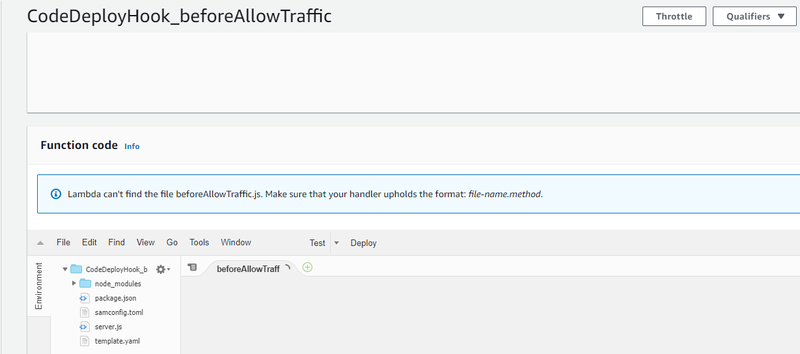
An example of the lambda editor with a small project layout and a helpful error message
The power of most modern languages and frameworks starts with the size of the ecosystem that offers you solutions to solve problems that you can apply rather than reinventing the wheel. Writing code without the ability to add numerous libraries - let alone if the language you want to use is compiled - quickly relegating the Lambda Console to the back-burner for anything more than gaining a trivial familiarity with the service.
Additional Infrastructure
One of the amazing opportunities Lamba offers users is to abstract compute operations into a component of their cloud infrastructure - but this alone will rarely be capable of providing the value of a full application. Just as running an EC2 machine without a database or a web server would make it impossible to serve dynamic web content, just writing code in Lambda does not an application make. Lambda provides the ability to be triggered by many other AWS services:
- API Gateway or ALB to manage web requests to use lambda to run webserver code
- EventBridge (formerly Cloudwatch Events ) to invoke functions for things such as background processing and scheduled tasks
- DynamoDB, Kinesis, and many other services to trigger code based on events occurring while suffering no wasted processing from polling, etc.
Just as none of these triggers can be utilized without a correspondingly configured source and defined integration, even a lambda within a VPC without appropriate subnet configuration won't be able to make requests to the Internet. Growing beyond using lambda as just "a place to run this bit of code" requires fully defined relationships between AWS services and appropriate security and networking policies to allow access to external services - making lambda a valuable part of the overall architecture, but not something that can do it all alone.
Project Management
While lambda functions are versioned, providing for the ability to track changes, this offers nothing in terms of code management that allows team sizes to grow. When coupled with proper code management tools such as git or AWS Code Pipeline, lambda versioning can be useful for rollbacks, and other features such as aliases provide similar functionality for things such as canary deployments, but managing this between multiple team members editing in the console UI is not feasible. The lambda editor is not a collaborative editing platform, and cannot replace best practice code management techniques.
Programmatic Tooling
The AWS CLI provides interfaces to all AWS services that can be interacted with via the console, allowing us to script changes to our services rather than create them manually. These tools are built upon the underlying boto3 protocol which provides an API that can be used in code, rather than as console commands. Along with CloudFormation, AWS provides all the tools necessary for a team to craft its own version of automated deployment and management with AWS services.

Cloudformation provides very detailed logs about stack creation steps and state transitions
Started to build our project stack at this level would introduce a few challenges in solving non-AWS problems, however:
- Lambda can take a properly packaged project and use it to serve up an application. However, packaging an application of additional complexity, especially in different languages that have different concerns, is not a problem for AWS to solve. For example, while the python runtime in lambda provides access to most common stdlib packages, there is no way for the service to reasonably know what packages that require external compiled dependencies might be used.
- Interactions between non-lambda services that also require additional steps also fall outside the responsibility of AWS tools. If we need to process images for compression or compile our sass/scss to css for deployment - this is not an AWS-specific concern. What if we are deploying an application that needs access to service static content and maybe even accept uploads? In this case, we may want to use S3 - but S3 is not a trigger if we want to use it as a destination for user-initiated actions, and it is also not inherently available to a function in lambda - it must be created and managed. While CloudFormation alone can help us with the state of the bucket, what about ensuring that the resource names line up between the deployed code and the buckets we create? CloudFormation will include whatever logic we template, but how are we managing consistencies between the state of our application and other resources?

Cloudformation provides all the pieces necessary for more complex template logic, but the syntax quickly becomes quite dense
- While CloudFormation offers a way to manage more complex resource and external relationships by the use of references that are exposed at runtime, managing these interactions requires explicit identification of numerous dependencies and does not assist us in preparing resources to interact with the resources managed by our CloudFormation templates. For example, if we want to get a package into our lambda we'll still need to compile and package it appropriately, and we'll still need to utilize the AWS CLI to actually upload the data for a new lambda version deployment. While CloudFormation helps us manage resource state, there will still be a lot of pieces required to join CloudFormation, the AWS CLI (or underlying boto protocol within scripts/programs), and our project idiosyncrasies into a manageable whole.
Conclusion
We quickly find ourselves wanting to leverage and build upon serverless frameworks created to address the complexity of the issues we might encounter if we start with these lower-level abstractions. In the second part of this series, we'll see how some well-known serverless frameworks manage this decision, and some tradeoffs JBS has experienced over the years. We'll dive deeper into the specifics of how one can quickly grow in their serverless expertise and manage projects reliably and professionally, delivering consistent results and allowing for faster iteration while extracting further value out of cloud resources.
Part two of this series can be viewed here.
The JBS Quick Launch Lab
Free Qualified Assessment
Quantify what it will take to implement your next big idea!
Our assessment session will deliver tangible timelines, costs, high-level requirements, and recommend architectures that will work best. Let JBS prove to you and your team why over 24 years of experience matters.



