A Brief Overview of Apache Spark
In the Apache Foundation’s own words, Spark is called “A fast and general engine for large scale data processing.” Parsing this we get: Fast – Spark relies on an in-memory processing model which
In the Apache Foundation’s own words, Spark is called “A fast and general engine for large-scale data processing.” Parsing this we get:
- Fast – Spark relies on an in-memory processing model which drastically reduces IO operations, and can be up to 100x faster than Hadoop on similar tasks
- General Purpose – Batch processing, interactive analytics, real-time streaming on one platform. (In addition to Graph computation, machine learning and others)
In addition to the above, Spark is also:
- Scalable – as with both Redshift and Hadoop, it is based on a node/cluster architecture
- Robust – node failure has no impact on processing; Spark keeps an equivalent of an RDBMs transaction log, it can redistribute data and recreate any operations on the data that was lost
- Easy to use – Rich, high level APIs in Python, Scala, R and SQL – out of the box.
- Flexible deployment options – Standalone, Hadoop, Mesos, etc…
Brief History
- Started in 2009 as a research project at UC Berkeley
- Hadoop was too inefficient for iterative type algorithms and interactive analysis that the researchers required – Spark was initially the result of creating a platform to address those needs
- At inception, it was already providing speed gains or 10x-20x over Hadoop on Map-Reduce jobs
- Open-sourced in 2010
- Spark Streaming was incorporated as a core component in 2011
- In 2013, Spark was transferred to the Apache Software foundation
- Spark 1.0 released in 2014, where it became the most actively developed and fastest growing Apache project in Apache’s history
- July 26th, 2016 Spark 2.0 released with major improvements in every area over the 1.x branches
Architectural Overview
The diagram below shows the major components and libraries of the main Spark architecture:

Outside of the major libraries and components in Spark (as shown above), the main architectural abstraction in Spark is the Resilient Distributed Dataset – RDD. RDDs are collections of elements partitioned across the nodes of the cluster and operated on in parallel. In addition, RDDs can be persisted in memory allowing very efficient parallel operations. RDDs are also very robust; they automatically recover from any node failures in the cluster. They can also be cached for efficiencies. All of Spark’s higher-level APIs – SparkSQL, Spark Streaming, MLib, and GraphX use RDDs under the hood. The diagram below illustrates the partitioned, distributed nature of RDDs:
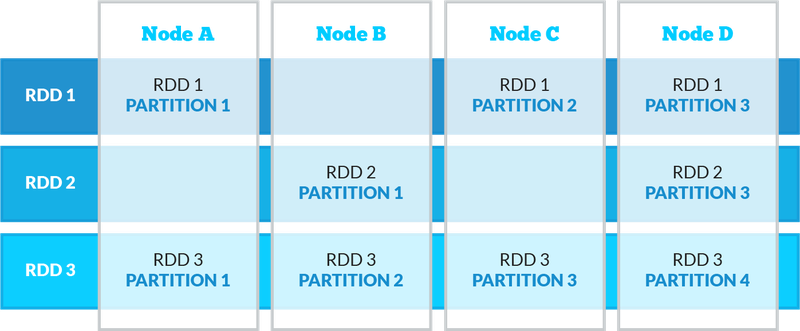
Aside from RDDs, the other important core architectural mechanism is the Shared Variable, of which there are:
- Broadcast variables – variables shared across tasks on each node
- Accumulators – variables that are only added to, such as counters or sums
By default, RDDs and Shared Variables are stored and operated on using an in-memory model; this makes processing very fast and efficient. RDD functionality is fully exposed and can be programmed directly using Spark’s lower-level API interface. In practice, 99% of Spark programming is typically done using the higher-level libraries (SparkSQL, MLib, etc…)
Spark also has several different deployment options, which can help integrate with existing legacy environments and gives it much flexibility:
- Stand-alone locally
- Stand-alone clustered
- Integrated into Hadoop (running on YARN)
Spark also comes out of the box with three different shells that allow an interactive workflow with the cluster:
- Python (pyspark)
- Scala (spark-shell)
- R (sparkR)
Of course, in addition to interactive usage through the various shells, you can always submit scripts to the cluster as batch jobs.
Spark SQL
Spark SQL is Spark’s module for working with structured data, and utilizes two different APIs:
- Direct SQL – cost bases query analyzer/planner and execution engine; columnar storage. External tools (such as BI tools) can connect to the Spark cluster via ODBC/JDBC. This essentially turns Spark into a distributed query engine. Also runs on top of Hadoop’s Hive
- DataFrame API (Similar and modelled after R/Panda dataframes)
Let’s look at some examples of how this works. First, let’s start up the pyspark shell:
Now that we’re in the shell and have SparkSession created for us (the premade SparkSession object is our gateway into Spark’s APIs). We can start to issue commands. First, though, we need to load some data into the cluster. Our data set has been provided by the City of Philadelphia, and provides various information on parking violations:
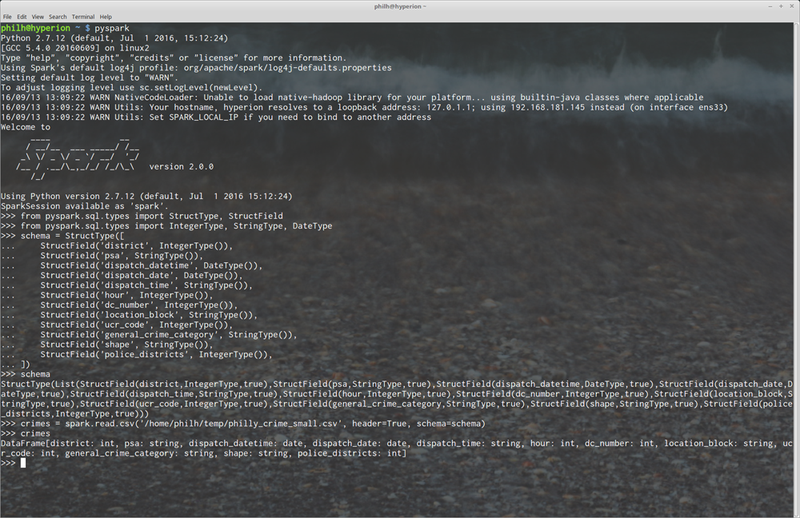
In the above screenshot of our shell, you can see we import some types and fields from Spark’s SQL library and then create a schema, so Spark can better infer our data that we will be working with. Next, we read the data into the cluster with the read.csv(…) method. When data is read in this way, we’re returned a DataFrame object, that is based on the schema we created earlier.
Now that we have some data to work with, let’s issue a SQL statement. To do this, we must first create either a Table or View in Spark, and then we can query that object using straight SQL:
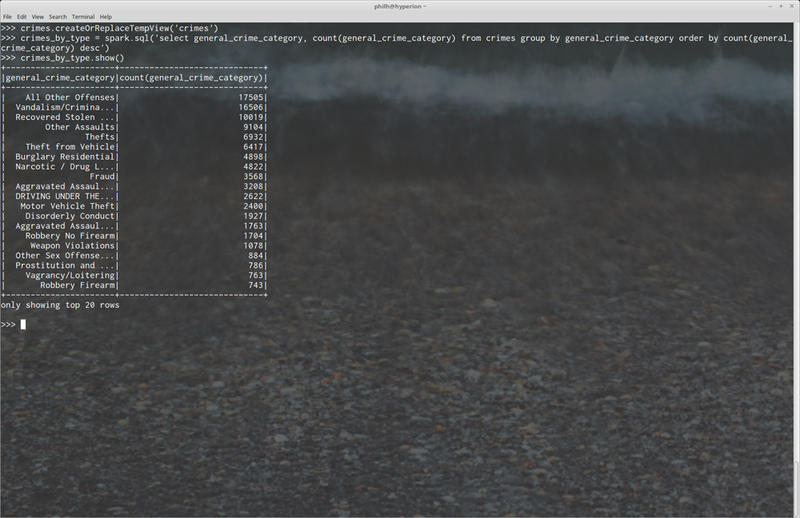
In the above, we can see us creating a view using the DataFrame’s createOrReplaceTempView(…) method (there are other ways to do this as well). Next, using the sql(…) method, we issue a SQL statement as if we were querying a table in a traditional RDBM system.
In addition to using SQL, we can also query the DataFrame directly using the DataFrame’s own API. Here is the same query that was issued above, using DataFrame methods:
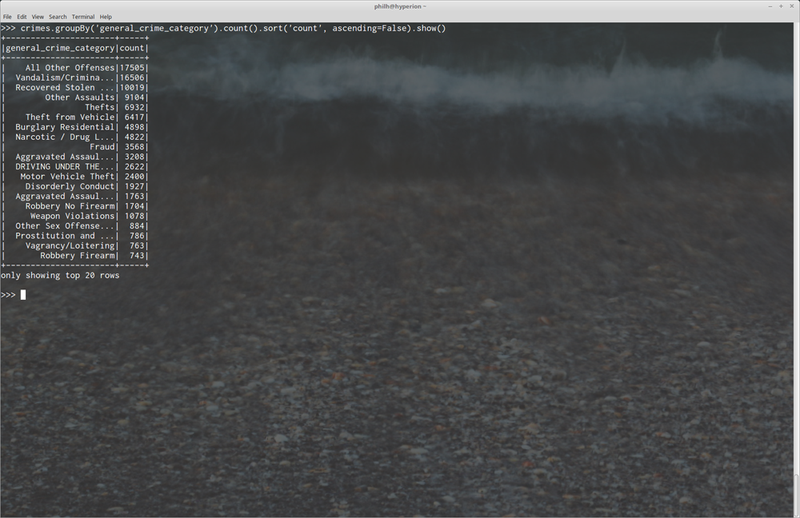
In addition to the query in the screenshot above, where perform a group by, count, and sort operations, we can also group by multiple columns and sort by multiple columns as well:
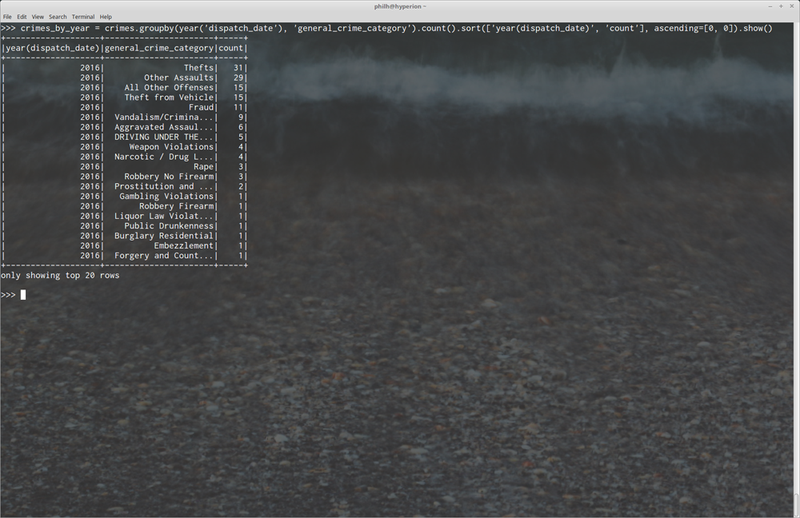
It is also easy to add derived columns to our dataset using the DataFrame API:
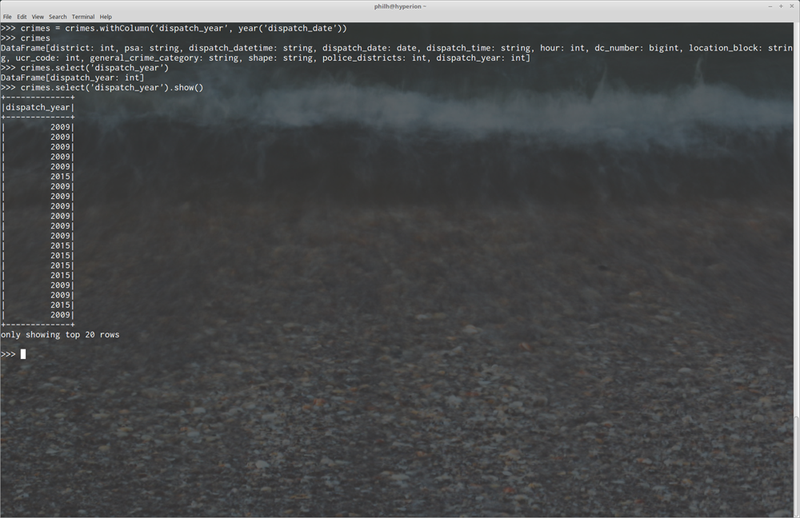
Here we’ve added a new column entitled, “dispatch_year” based on the dispatch_date’s year value.
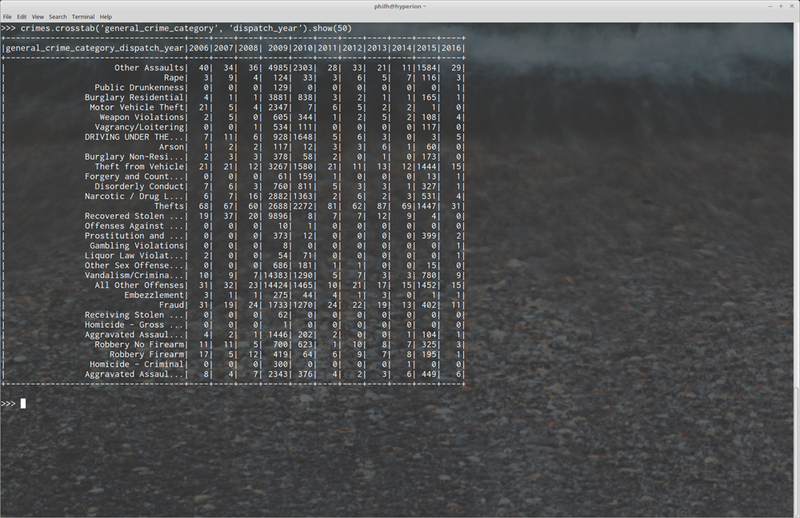
We can now use that column as if it was part of the original dataset. Here is an example of the crosstab functionality available to the DataFrame (this is also an example of something very tedious and difficult to do using straight SQL constructs):
In addition to the commands shown above, the DataFrame object comes with a very feature-rich, comprehensive API. Here is some of the available functionality:
- Statistics – Avg, mean, correlations, covariances, deviations, similarities (Pearson), etc. Also includes functions for sampling data
- Null and missing data functions (default values, custom values, functions, average values, etc)
- Data type casting and conversion functions
- Column functions – add, remove, updates, etc…
- Row functions for single-row operations
- De-duplication of data functions
- Functions for saving to json, external storage, pandas, among others
Spark – Data
An important question that beginners usually have is, “In a clustered environment like this, where does the data actually live?”
First off, Spark can read data out of the local file system, HDFS, S3, ODBC/JDBC databases, Cassandra, etc… When data is read from these sources, the cluster manager partitions the data across the nodes in memory and into an RDD. However, depending on where the data is coming from, Spark can optimize heavily. For example, if the data is stored on HDFS, Spark can make sure that the data for that node is coming from the part of the file that is stored on that node – massively decreasing the amount of I/O operations. Also when using HDFS, Spark natively can take advantage of some of the more advanced file and serialization formats such as Avro and Parquet. Avro and Parquet are columnar file formats, so reading data from them into an RDD is very fast and very efficient. This is a very similar model to how a data store like Amazon Redshift works internally.
Additional Libraries
(A very brief high-level overview of additional high-level components and libraries Spark comes with)
MLlib
MLlib is Spark’s built-in native machine learning library. It contains a rich, comprehensive library of distributed machine learning algorithms. Algorithms for feature extraction, classification, regression, clustering, recommendations, among many others are included “out of the box”. It also contains both supervised and unsupervised algorithms. In addition, Spark also includes other tools important for machine learning processes:
- Pipelines for building workflows between ML algorithms
- CrossValidator – a parameter tuning tool
- Model persistence – can save/load models created with any of the above types of algorithms
Spark’s MlLib can also natively interact with libraries such as Python’s NumPy and R’s standard libraries.
GraphX
GraphX is Spark’s native built-in libraries and API for working with graphs and graph-parallel computation. It comes with many well-known graph algorithms out of the box, such as:
- PageRank
- Connected Components
- Strongly Connected Components
- SVD++
- And many others
Graph data ca automatically be viewed in either Graph or collection (Tabular) formats, and Graphs and RDDs can be joined together for more complex querying. The Edges and vertices can be cached for efficiency and performance purposes.
In addition to many common graph algorithms, GraphX comes with an extremely rich set of operators for graph operations
- Structural Operators
- Join Operators
- Aggregations
- Operators for computing various degrees
Streaming
Spark Streaming is Spark’s built-in, native library for building fault-tolerant, distributed streaming applications. This is similar to Apache Storm, Apache Samza, Apache Flink, and other streaming platforms. Can use the same code written for either batch or interactive methods – no special, specific coding needed for streaming. Can recover lost work and operator state (if you're using sliding windowing functions for example). Streams can be integrated against any other RDD, regardless of the source.
The JBS Quick Launch Lab
Free Qualified Assessment
Quantify what it will take to implement your next big idea!
Our assessment session will deliver tangible timelines, costs, high-level requirements, and recommend architectures that will work best. Let JBS prove to you and your team why over 24 years of experience matters.



